Turn ZFS mirror to RaidZ
Introduction
Recently, I’ve noticed that I’m running out of space on my ZFS pool on my NAS. I initially set up this pool as a mirror, thinking I would never run out of 8TB of space. Well, here we are, two years later, and I need to add more space.
Unfortunately, there is no easy, native, or safe way to do this when you only want to buy one new HDD. The alternatives are either adding another mirror or buying three new disks and creating a new pool with them.
During my research, I stumbled upon this archived post by Fan Zhang from Privacyhold (a now-defunct site). In this post, he describes a way to trick both the old mirror pool and the new RAIDZ pool into functioning simultaneously, allowing data to be copied over.
The post is from 2008, and some commands are now deprecated. I decided to create an updated version. However, his explanation remains accurate, and you can read either his post or mine below »
High level overview
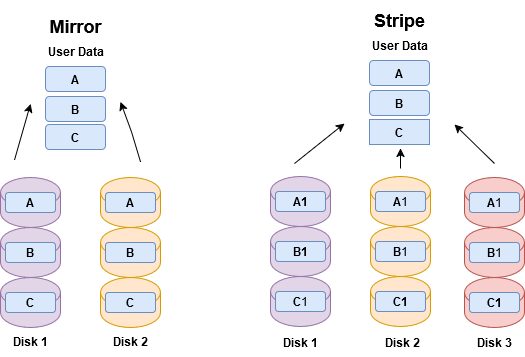
How ZFS Mirror Works
The way zfs mirror works is that we have 2 drives, and data is replicated 1:1 between them—meaning you can lose up to 1 drive before losing data (out of 2 drives)
The way zfs RAIDZ1 works is that we have 3 drives and data is “striped” across all of them in parallel—meaning you can up to 1 drive before losing data (out of 3 drives)
How ZFS RAIDZ1 Works
- We use that we can lose 1 drive in our mirror pool, use that drive + new bought one + fake loopback device (I’ll explain this later) to create the desired new RAIDz pool.
Migration Plan
Use the redundancy in the mirror pool to detach one drive.
Combine the detached drive, a new HDD, and a fake loopback device (explained later) to create the desired RAIDZ1 pool.
Both pools will be degraded but functional. While both pools are operational, copy the data over.
After completing the migration, destroy the old pool and replace the loopback device with the remaining disk from the old mirror.
This process is very dangerous and can lead to complete data loss. Since data is copied from a single drive, if that drive fails, all data is gone. Additionally, the copying process stresses the drive, increasing the likelihood of failure.
Steps
Gather Drive and Pool Information
I should point out * pool-01 = old pool (mirror) * pool-02 = new pool (raidz)
Identify the New Empty Drive
We can get this information in many ways. I like to compare the drive that has a partition on it and the one that doesn’t.
1
2
3
4
5
6
7
8
ls -lh /dev/disk/by-id|grep -A1 wwn|grep -v part
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5000c500e6c08d36 -> ../../sdf
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5000c500e6d9fdd3 -> ../../sde
lrwxrwxrwx 1 root root 9 Jan 7 20:56 wwn-0x5000c500f7dc72e5 -> ../../sdg
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5001b444a8db9658 -> ../../sdc
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5dc663a341b1f80e -> ../../sda
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5dc663a341b1f8cb -> ../../sdb
1
2
3
4
5
6
7
8
9
10
11
ls -lh /dev/disk/by-id|grep -A1 wwn|grep -v part1
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5000c500e6c08d36 -> ../../sdf
lrwxrwxrwx 1 root root 10 Dec 26 15:28 wwn-0x5000c500e6c08d36-part2 -> ../../sdf2
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5000c500e6d9fdd3 -> ../../sde
lrwxrwxrwx 1 root root 10 Dec 26 15:28 wwn-0x5000c500e6d9fdd3-part2 -> ../../sde2
lrwxrwxrwx 1 root root 9 Jan 7 20:56 wwn-0x5000c500f7dc72e5 -> ../../sdg
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5001b444a8db9658 -> ../../sdc
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5dc663a341b1f80e -> ../../sda
lrwxrwxrwx 1 root root 10 Dec 26 15:28 wwn-0x5dc663a341b1f80e-part9 -> ../../sda9
lrwxrwxrwx 1 root root 9 Dec 26 15:28 wwn-0x5dc663a341b1f8cb -> ../../sdb
lrwxrwxrwx 1 root root 10 Dec 26 15:28 wwn-0x5dc663a341b1f8cb-part9 -> ../../sdb9
We can see drive “wwn-0x5000c500f7dc72e5 -> ../../sdg” doesn’t have a partition as the only one.
Your drives will probably have different name so adjust grep accordingly.
This process is very dangerous and can lead to complete data loss. Since data is copied from a single drive, if that drive fails, all data is gone. Additionally, the copying process stresses the drive, increasing the likelihood of failure.
Names of pool and drives from the old pool
1
2
3
4
5
6
7
8
9
10
11
12
zpool status
pool: pool-01
state: ONLINE
scan: scrub repaired 0B in 08:58:13 with 0 errors on Sun Nov 17 08:58:14 2024
config:
NAME STATE READ WRITE CKSUM
pool-01 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
wwn-0x5000c500e6c08d36-part2 ONLINE 0 0 0
wwn-0x5000c500e6d9fdd3-part2 ONLINE 0 0 0
Detach one drive from the mirror
1
2
3
4
5
6
7
8
9
10
11
12
13
14
zpool detach pool-01 wwn-0x5000c500e6d9fdd3
root@gandalf:~# zpool status
pool: pool-01
state: ONLINE
scan: scrub repaired 0B in 08:58:13 with 0 errors on Sun Nov 17 08:58:14 2024
config:
NAME STATE READ WRITE CKSUM
pool-01 ONLINE 0 0 0
wwn-0x5000c500e6c08d36-part2 ONLINE 0 0 0
We can see the pool is now broken with only one drive, but still online.
Recap - Current status
-1x broken mirror zpool (pool-01) -1x used HDD (wwn-0x5000c500e6c08d36) in a pool-01 -2x free HDD (“wwn-0x5000c500e6d9fdd3” and “wwn-0x5000c500f7dc72e5”)
If you have cache and logs detach them now
In my case I don’t, but it’s a good thing to point it out.
1
2
zpool remove nvme-logs111
zpool remove nvme-cache
Sparse file (mentioned fake looback device)
To create raidz pool we need 3x disks. Zfs won’t allow us to create a pool without supplying them on the initialization of the pool. To get around this, we can create this mentioned fake loopback device with the help of sparse file and loopback devices.
I liked the explanation from the original post:
Loopback allows you to use a file the same way you’d use any other block device in /dev.
A sparse file is a type of file where the filesystem only stores its beginning and end pointer information and a size. The actual contents of the file aren’t stored until you begin to write to them. This allows us to do things like create a 140GB file on a 140GB disk with plenty of room to spare. And that’s precisely what we’ll do..
Some things has changed since orignal post, we need much more space than 140Gb. We need 8tb in our case, which hits limitations of some of the filesystems. That’s why I recommend you to create the sparse file on the zfs filesystem (yes it can be on the disk we are migrating now)
What size should a sparse file be
We are going to do some math here, so we know how big (precisely) we need
Get the size of one drives you used in mirror
1
2
3
4
5
6
7
8
9
lsblk
....
Disk /dev/sdg: 7.28 TiB, 8001563222016 bytes, 15628053168 sectors
Disk model: ST8000VN004-3CP1
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
...
We can see the size of the disk is 8001563222016 bytes. Divide that by 1024.. 8001563222016:1024=7814026584 And subtract 1 ….7814026584-1=7814026583
This is the size we are going to use “7814026583”. But the same math and process apply to all disk sizes.
Create sparse file
1
dd if=/dev/zero of=/media/disk.img bs=1024 seek=7814026583 count=1
- bs is block size, 1kb
- seek is the number of blocks to skip (and is equal to the size of the drive in bytes because of the previous bs= line ),
- and count tells dd to copy one block.
Check the size of the file
1
2
3
#needs to match physical drive size of 8001563222016 (which we got from lsblk)
du --bytes /pool-01/disk.img
8001563222016 /pool-01/disk.img
Mount the device
First check the loopback name we are going to use
1
2
losetup -f
/dev/loop0
After that run
1
losetup /dev/loop0 /pool-01/disk.img
Recap - Current status
- 1x broken mirror zpool (pool-01)
- 1x used HDD (wwn-0x5000c500e6c08d36) in a pool-01
- 2x free HDD (“wwn-0x5000c500e6d9fdd3” and “wwn-0x5000c500f7dc72e5”)
- sparse file the size of those disks
Create new raidz pool
We are going to use our 2x free disks and 1x sparse file
1
zpool create pool-02 raidz wwn-0x5000c500e6d9fdd3 wwn-0x5000c500f7dc72e5 /dev/loop0
Check the status. We can see both the old pool (pool-01) and the new pool (pool-02)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
zpool status
pool: pool-01
state: ONLINE
scan: scrub repaired 0B in 08:58:13 with 0 errors on Sun Nov 17 08:58:14 2024
config:
NAME STATE READ WRITE CKSUM
pool-01 ONLINE 0 0 0
wwn-0x5000c500e6c08d36-part2 ONLINE 0 0 0
errors: No known data errors
pool: pool-02
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
pool-02 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
wwn-0x5000c500e6d9fdd3 ONLINE 0 0 0
wwn-0x5000c500f7dc72e5 ONLINE 0 0 0
loop0 ONLINE 0 0 0
errors: No known data errors
Break the new raidz pool-02
We need to disable the fake loopback device created from the sparse file so the zfs won’t actually write data on it.
This command disables pool-02, unmounts the device and deletes the sparse file.
1
zpool offline pool-02 /dev/loop0 && losetup -d /dev/loop0 && rm /pool-01/disk.img
Check the status of the zfs pools
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
zpool status
pool: pool-01
state: ONLINE
scan: scrub repaired 0B in 08:58:13 with 0 errors on Sun Nov 17 08:58:14 2024
config:
NAME STATE READ WRITE CKSUM
pool-01 ONLINE 0 0 0
wwn-0x5000c500e6c08d36-part2 ONLINE 0 0 0
errors: No known data errors
pool: pool-02
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using 'zpool online' or replace the device with
'zpool replace'.
config:
NAME STATE READ WRITE CKSUM
pool-02 DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
wwn-0x5000c500e6d9fdd3 ONLINE 0 0 0
wwn-0x5000c500f7dc72e5 ONLINE 0 0 0
loop0 OFFLINE 0 0 0
errors: No known data errors
We can see the pool-02 has become degraded, but it’s still online so we can write data on it!
Copy data over from old (pool-01) to new (pool-02)
List all your zfs datasets
1
2
3
4
5
6
zfs list | grep pool-01
pool-01 6.31T 847G 112K /pool-01
pool-01/MediaServer 5.83T 847G 5.83T /pool-01/MediaServer
pool-01/data3 364G 847G 189G /pool-01/data3
pool-01/samba 128G 847G 128G /pool-01/samba
pool-01/subvol-116-disk-0 1.37G 6.63G 1.37G /pool-01/subvol-116-disk-0
Create data sets in the new pool (pool-02) for all the datasets from the old pool (pool-01) that we just listed
1
zfs create pool-02/MediaServer && zfs create pool-02/data3 && zfs create pool-02/samba && zfs create pool-02/subvol-116-disk-0
Rsync the data
For copying the data I’ve decided to use rsync as it’s a better variation of cp. But mainly if anything happens, you don’t need to start over with the copy process.
You can either
1
2
3
4
5
#rsync manual option
rsync -ah --info=progress2 /pool-01/subvol-116-disk-0 /pool-02/subvol-116-disk-0
rsync -ah --info=progress2 /pool-01/MediaServer/ /pool-02/MediaServer/
rsync -ah --info=progress2 /pool-01/data3/ /pool-02/data3/
rsync -ah --info=progress2 /pool-01/samba/ /pool-02/samba/
or
1
2
#rsync one liner
rsync -ah --info=progress2 /pool-01/subvol-116-disk-0 /pool-02/subvol-116-disk-0 && rsync -ah --info=progress2 /pool-01/data3/ /pool-02/data3/ && rsync -ah --info=progress2 /pool-01/MediaServer/ /pool-02/MediaServer/ && rsync -ah --info=progress2 /pool-01/samba/ /pool-02/samba/
This is going to take few/many hours. For me it was arround 12hours.
Destroy the old pool (pool-01)
When you are done with the data migration and you are sure you got everything (double run the rsync just in case) we can destroy the old pool:
1
zpool destroy pool-01
Replace drive in new pool (pool-02) for actual drive
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
zpool replace pool-02 loop0 wwn-0x5000c500e6c08d36
root@gandalf:~# zpool status
pool: pool-02
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Wed Jan 8 12:25:36 2025
1.69T / 10.1T scanned at 59.5G/s, 0B / 10.1T issued
0B resilvered, 0.00% done, no estimated completion time
config:
NAME STATE READ WRITE CKSUM
pool-02 DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
wwn-0x5000c500e6d9fdd3 ONLINE 0 0 0
wwn-0x5000c500f7dc72e5 ONLINE 0 0 0
replacing-2 DEGRADED 0 0 0
loop0 OFFLINE 0 0 0
wwn-0x5000c500e6c08d36 ONLINE 0 0 0
As you can see the ZFS already started to replace the missing drive.
(Optional) Rename the zfs pool
I wanted to keep the old name, for the old links and stuff, but you can keep the new name if you like.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
root@gandalf:~# zpool export pool-02
root@gandalf:~# zpool import pool-02 pool-01
root@gandalf:~#
root@gandalf:~# zpool status
pool: pool-01
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Wed Jan 8 12:25:36 2025
4.59T / 10.1T scanned at 13.5G/s, 157G / 10.1T issued at 461M/s
52.4G resilvered, 1.52% done, 06:17:26 to go
config:
NAME STATE READ WRITE CKSUM
pool-01 DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
wwn-0x5000c500e6d9fdd3 ONLINE 0 0 0
wwn-0x5000c500f7dc72e5 ONLINE 0 0 0
replacing-2 DEGRADED 0 0 48
loop0 OFFLINE 0 0 0
wwn-0x5000c500e6c08d36 ONLINE 0 0 0 (resilvering)
Congratulations
Enjoy new space!